Tools:
The models are:
![]()
![]()
![]()
![]()
Now use the rotating 3-D plot to view the data. Does this change your guesses?
![]()
![]()
![]()
![]()
![]()
As we did for SLR model, we use least squares to fit the MLR
model. This means finding estmators of the model parameters
![]() and
and ![]() . The LSEs of the
. The LSEs of the
![]() s are those values, of
s are those values, of ![]() , denoted
, denoted
![]() ,which minimize
,which minimize
![]()
![\begin{displaymath}
\sum_{i=1}^n[Y_i-(b_0+b_1 X_{i1}+b_2 X_{i2}+\cdots +b_q X_{iq})]^2.\end{displaymath}](img18.gif)
![]()
![]()
Let's see what happens when we fit models to sasdata.eg10_2a and sasdata.eg10_2c.
Residuals and studentized residuals are the primary tools to analyze model fit. We look for outliers and other deviations from model assumptions. Let's look at the residuals from some fits to sasdata.eg10_2c.
The intercept has the interpretation ``expected response when the Xi
all equal 0''. The coefficient ![]() is interpreted as the
change in expected response per unit change in Xi when the other
Xs are held fixed (if that is possible).
is interpreted as the
change in expected response per unit change in Xi when the other
Xs are held fixed (if that is possible).
Otherwise can interpret the model using multivariate calculus: change in expected response per unit change in Zi (with the other predictors held fixed) is
![]()
![]()
![]()
Two ways of building models:
Idea:
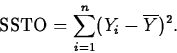
residuals. It measures the variation of the response unaccounted for by the fitted model or the uncertainty of predicting the response using the fitted model.
The degrees of freedom for a SS is the number of independent pieces of data making up the SS. For SSTO, SSE and SSR the degrees of freedom are n-1, n-q-1 and q. These add just as the SSs do. A SS divided by its degrees of freedom is called a Mean Square.
This is a table which summarizes the SSs, degrees of freedom and mean squares.
| Analysis of Variance | |||||
| Source | DF | SS | MS | F Stat | Prob > F |
| Model | q | SSR | MSR | F=MSR/MSE | p-value |
| Error | n-q-1 | SSE | MSE | ||
| C Total | n-1 | SSTO |
| H0: | |
| Ha: | Not H0 |
| H0: | |
| Ha: |
![]()
![]()
![]()
A
level
L prediction interval for a new response at predictor values
![]() is
is
![]()
![]()
![]()
![]()
Multicollinearity is correlation among the predictors.
Selection of variables in empirical model building is an important task. We consider only one of many possible methods: backward elimination, which consists of starting with all possible Xi in the model and eliminating the non-significant ones one at at time, until we are satisfied with the remaining model.